GPU cuda kernel
https://keepdev.tistory.com/36
https://karl6885.github.io/cuda/2018/11/08/NVIDIA-CUDA-tutorial-1/
https://chowdera.com/2022/01/202201300202472257.html
http://uniteseoul.com/2019/PDF/D2T5S1.pdf
1) GPU under the hood: deep learning practitioners' perspective
첫 번째 강연은 딥러닝 어플리케이션 성능을 분석하고 이해하는 방법에 대해 설명해주셨다.
<주제>
Operation Speed
- Latency
- Throughput
Model Accuracy에 대해서가 아닌, latency와 throughput 성능을 통해 서비스 퀄리티를 향상시키고(response time 향상), GPU를 효율적으로 이용할 수 있는 방법에 대한 내용이 주제였다.
<Training Performance>
- CPU와 GPU의 관계
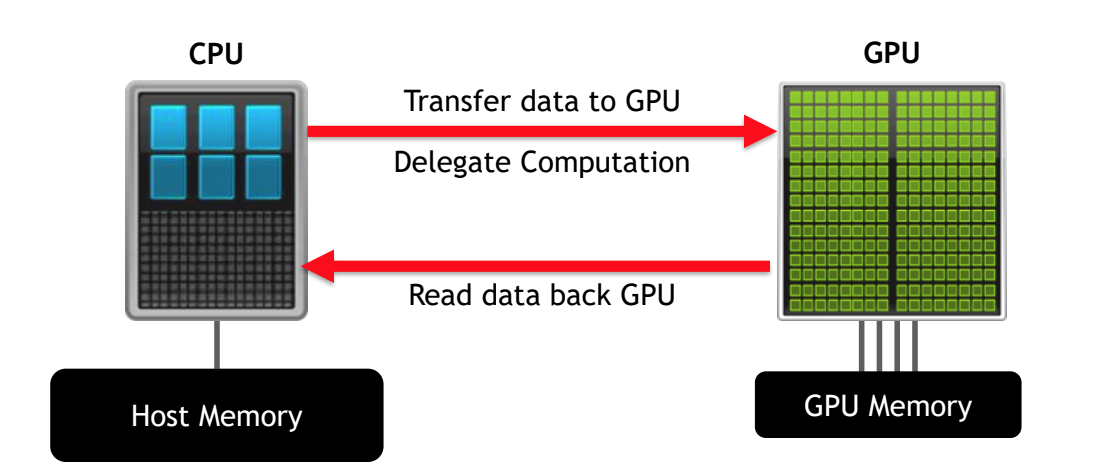
CPU는 GPU에 data를 보내서 연산을 시키고, 연산된 결과 데이터를 GPU가 다시 CPU로 보낸다.
- Model의 forward, backward pass를 보면, 각각의 layer의 operation은 GPU의 CUDA kernel에서 계산된다.
< Categories of Deep Learning Kernels>
- Element-wise kernels(memory > computation): ReLU, scale, add, and so on
- Reduction kernels: Batch Normalization, Softmax, etc.
- Dot-product kernels(memory < computation): matrix-vector or matrix-matrix multiply kernels such as FC and CONV
<Compute Bound vs. Memory Bound>
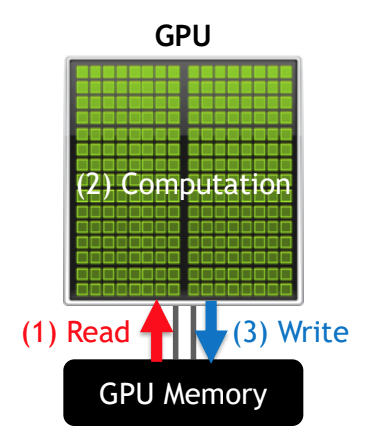


- Compute Bound: Compute utilization > Memory utilization
즉 computational problem을 해결할 때, 시간을 주로 계산하는데 쓰냐(compute), memory를 사용하는데 쓰냐(memory)인데, compute bound는 계산하는데 걸리는 시간이 문제를 해결하는데 주로 차지하는 시간이라는 의미이다.
- Memory Bound: Compute utilization < <Memory utilization
Memory bound는 computational problem을 해결할 때, memory를 읽어오고 적재하고 사용하는 등의 memory utilization에 주로 시간이 많이 걸린다는 의미이다.
위의 내용을 확인해서 CUDA kernel이 GPU를 효율적으로 쓰고있는데 맞는지 확인한다
만약 효율적으로 GPU를 사용하고 있지 않다면, 퍼포먼스를 향상시키기 위해 high-level guidance가 필요하다



댓글
댓글 쓰기